Anti-scraping people are tiring.
Federation duplicates data and the way masto is built, masto's federation backs it up for perpetual availability.
Scraping and archiving is another side of the same coin.
You opt into having a permanent record of your digital activity when you start posting online.
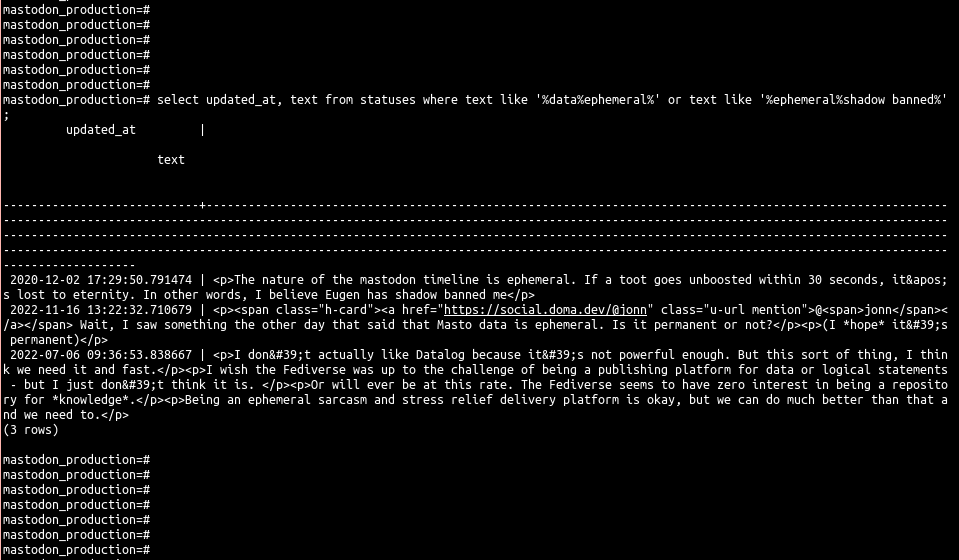
@jonn Wait, I saw something the other day that said that Masto data is ephemeral. Is it permanent or not?
(I *hope* it's permanent)
@nafnlaus one query is better than a thousand words.
Stuff we interact with gets permanently cached on our instances.
Maybe big instances work differently, but it's a matter of coping with scale rather than a design choice.
{kind=link}
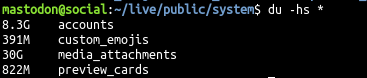
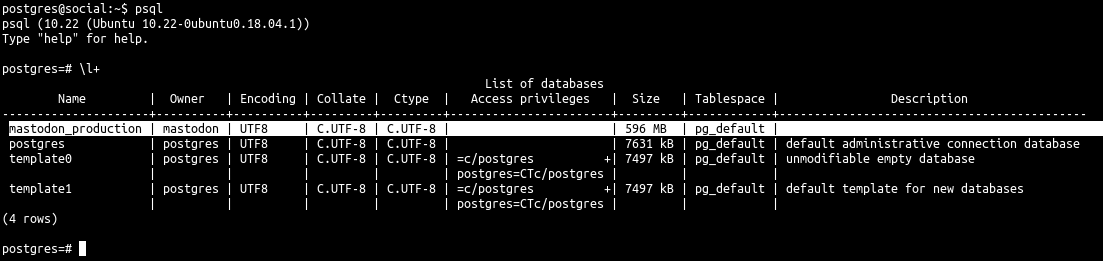
@jonn Hey, while I have you here, is it possible for you to check - how much of the stored data is text vs. images vs. video?
(I'm also curious what the distribution of images served is (e.g. are the vast majority a small subset at any given time that could cache well?), but it's more complicated to investigate, so I won't bug you with it).
This relates to this issue: https://github.com/mastodon/mastodon/issues/20255
@nafnlaus oh fuck, I have to increase the size of the instance or purge media files somehow. 🤔
{kind=link}
{kind=link}
@nafnlaus the instance is up since Autumn 2021, so for roughly a year.
@jonn It's not clear to me - what's the ratio between text, images and video?
The issue in question is various things that can be done to simultaneously increase image quality (which we're getting complaints about) while decreasing image storage size (which is always an issue). But some of the possibilities have complications, such as dealing with legacy clients.
@nafnlaus ah, ok, let me find videos I guess.
@jonn Right now we're only using JPEG (and PNG, strangely, despite them being massive!) But also, rather than controlling file size, we're simply aggressively downscaling them - when you get a better compression/quality ratio with less downscaling but a lower CRF. We could also support WebM (~75% the size) and (AVIF is ~50% the size), but then we'd need a caching image proxy server for legacy clients, so the question arises what sort of ratio of cache hits we might get.
@jonn Honestly, though, with a mix of fingerprinting, modern image formats (with imgproxy for serving to legacy clients), proper image handling, etc I suspect we'd get *over* an order of magnitude increase in user capacity for a given amount of disk space.

@jonn Fingerprinting *exact* matches is pretty easy, but gets a bit trickier when you're dealing with inexact matches, though. Metadata may be different, JPEG compression noise different, resolution different, etc. There are readily available hash algos to create unique hashes independent of this sort of stuff, but it does add complications (like, for example, making sure you only store the highest-quality version).